Comparing the Uncomparable to Claim the State of the Art: A Concerning Trend
Spotting evaluation errors and speculative claims in GPT-3, PaLM, and AlexaTM.
In AI research, authors of scientific papers often choose to directly compare their own results with results published in previous work, assuming that these results are all comparable. In other words, researchers perform a simple copy of previous work’s numbers for a comparison with their own numbers, instead of reproducing days or even weeks of experiments, to demonstrate that their new method or algorithm improves over previous work.
This simple copy sounds very convenient and intuitive! What’s the catch?
In this article, I demonstrate that the convenience of copying previous work’s numbers often comes at the cost of scientific credibility. I describe how uncomparable numbers happen to be compared in scientific papers. Then, I review some concrete examples of flawed comparisons from very well-known and recent work, namely, Open AI’s GPT-3, Google’s PaLM, and Amazon Alexa AI ‘s AlexaTM. This part is a bit heavy in details, but I hope it can also help you to understand how to spot sloppy evaluations and speculative claims by yourselves in research papers. Before concluding, I also discuss how copying numbers from previous work for evaluation costs us much more than just scientific credibility.
This article doesn’t target a specific audience. I avoid technical details and try to make my demonstrations as simple as possible while providing you all the material you may need to verify my conclusions. I describe machine translation examples since this is my area of expertise. My observations are also applicable, but probably to a much lesser extent, to other research areas of natural language processing such as summarization, dialogue response generation, question answering, and paraphrasing.
A Single Name for Many Metrics
Let’s take machine translation research as an example. To publish scientific papers at top-tier conferences, machine translation researchers have to demonstrate that the new method/algorithm proposed yields a better translation quality than previous work.
Almost 100% of machine translation papers use the metric BLEU to automatically evaluate translation quality. BLEU evaluates how similar a machine translation output is to a given reference translation produced by a human. If the machine translation output is more similar to the reference translation, the BLEU score will go up, and the translation will be considered better. To have a paper accepted for publication at top-tier conferences, researchers in machine translation are usually required by expert reviewers to show that they have higher BLEU scores than previous work. If you open a machine translation paper, I can almost guarantee that you will find the claim of a BLEU improvement. More particularly, you will find tables that list machine translation systems with their corresponding BLEU scores.
For instance, I listed in the following table 6 machine translation systems and computed a BLEU score for each. The details of these systems are irrelevant for now. All BLEU scores are computed for a translation from English into French of the same news articles, namely WMT14 newstest dataset which is still often used in machine translation research.
Keep in mind that, for the purpose of my demonstration, we will trust BLEU at 100% to follow the evaluation standard in machine translation: Higher BLEU means better translation quality, and a difference of more than 1 BLEU between two systems is significant.
|
Machine Translation System |
BLEU Score |
|
#1 |
37.0 |
|
#2 |
37.0 |
|
#3 |
37.7 |
|
#4 |
38.1 |
|
#5 |
35.8 |
|
#6 |
39.0 |
Which system is the best according to BLEU?
You would probably answer #6 since it has the highest score. You could even say that #6 is significantly better than #5, right?
Actually, all the systems in the table are the same and I computed the BLEU scores for the same translation. So why are the scores different? Note: For this example, I used the translation output submitted by the University of Edinburgh to the WMT14 translation task.
“BLEU is not a single metric.” Matt Post, A Call for Clarity in Reporting BLEU Scores (2018)
The only difference for each row is that I used different tokenizations. Here, tokenization is a process that splits sentences into smaller sequences of characters called tokens. BLEU is a tokenization dependent metric. The machine translation output and the reference translations are tokenized with the same tokenizer. There are many ways to tokenize and often with small differences, particularly for European languages for which spaces between words are often used to obtain reasonable tokens.
So, here we have different BLEU scores, for the same translation, but processed differently for evaluation purposes only. This example should already be enough to convince you that BLEU scores computed with different tokenizations can’t be compared. Yet, as I will show in the next section, machine translation papers often compared their BLEU scores computed, let’s say with tokenization #5, with previously published BLEU scores computed with tokenization #4, and then conclude that their translation is better without even considering that they may have obtained higher BLEU only due to the use of a different tokenization.
Let’s talk a bit more about tokenization.
In the following table, I unveil the tokenization methods I used above with examples in French extracted from the reference translation. Note: You don’t need to understand the examples. We will only look at the differences between tokenizations.
|
Tokenizer |
Example 1 Example 2 |
|
None (Original) |
« Je savais que je n'étais pas une fille », a-t-il déclaré sur ABCNews.com. Les spectacles musicaux comblent ce [non-printable-char]manque. |
|
#1 Moses Tokenizer 2022 |
« Je savais que je n' étais pas une fille » , a-t-il déclaré sur ABCNews.com . Les spectacles musicaux comblent ce [non-printable-char] manque . |
|
#2 Moses Tokenizer 2017 |
« Je savais que je n' étais pas une fille » , a-t-il déclaré sur ABCNews.com. Les spectacles musicaux comblent ce [non-printable-char] manque . |
|
#3 Moses Tokenizer 2022 Aggressive |
« Je savais que je n' étais pas une fille » , a @-@ t @-@ il déclaré sur ABCNews.com . Les spectacles musicaux comblent ce [non-printable-char] manque . |
|
#4 Moses Tokenizer 2022 XLM |
" Je savais que je n' étais pas une fille " , a-t-il déclaré sur ABCNews.com . Les spectacles musicaux comblent ce manque . |
|
#5 SacreBLEU 13a |
« Je savais que je n'étais pas une fille » , a-t-il déclaré sur ABCNews . com . Les spectacles musicaux comblent ce [non-printable-char]manque . |
|
#6 SacreBLEU intl |
« Je savais que je n ' étais pas une fille » , a - t - il déclaré sur ABCNews . com . Les spectacles musicaux comblent ce [non-printable-char]manque . |
Note: I added by hand “[non-printable-char]” to indicate that there is a character that won’t print (but still exploited to compute BLEU).
The Moses tokenizer is one of the most used tokenizers for European languages. Some differences are difficult to spot but all 6 tokenizations are different (watch for the spaces). Moses tokenization’s rules have been updated in 2017. Periods are handled differently. Basically, you can assume that comparisons of scores computed on a Moses tokenization after 2018 with scores computed in 2017 or earlier are incorrect. For the entire WMT14 test set (around 3,000 sentences), #1 generates a dozen tokens more than #2. It looks insignificant and the BLEU scores (37.0) look identical. It doesn’t mean that for other texts there won’t be a larger difference in BLEU. Assuming that two different tokenizations will yield similar results is a gamble and won’t allow us to draw any valid scientific conclusions. For some other test sets from WMT evaluation campaigns (for instance, pl-en WMT20), I did observe differences in BLEU between Moses Tokenizer 2017 and 2022.
The XLM tokenization (#4) is very heavy in terms of normalization and tends to inflate BLEU scores. It has been used to evaluate XLM, GPT-3, and potentially many other papers. In contrast, the internal default tokenizer 13a of SacreBLEU (#5) is rather minimalist and preserves the original text as much as possible. Yet, despite their differences, I could easily find examples in published papers of scores computed with #4 compared against scores computed with #5 (see the next section).
All these tokenization methods are commonly used by machine translation researchers.
Small differences in the tokenization process can lead to what researchers commonly call significant differences in terms of BLEU. Back to our original problem, if BLEU scores are copied from previous work and compared, we should verify and be absolutely certain that all BLEU scores are computed with the same tokenizer (version, options, etc.), otherwise there are chances that we may achieve a new ‘state of the art’ simply based on very convenient but incorrect comparisons…
Here, I took the example of the Moses tokenizer which is one of simplest tokenizers used in machine translation. You can generate many more tokenization variants with tokenizers for other languages, especially Asian languages such as Japanese and Chinese.
Different tokenizations also lead to different rankings of systems. In other words, the best system is not always the best depending on the tokenization we choose to compute BLEU. I won’t demonstrate it, but there is an example in Table 12 and Table 13 of Adelani et al. (2022) where we can see that SacreBLEU tokenization and spBLEU tokenization yield different rankings.
Now you may wonder:
Are there really research papers presenting comparisons of scores computed differently for evaluation? Yes.
Can it really lead to wrong conclusions? Yes.
Is it easy to find that copied scores are computed differently? No.
How often does it happen? Quite often.
If you read my review of No Language Left Behind, you will find that the main issue I describe here is the same: Considering that two numbers are comparable while computed by different metrics.
Let’s have a look at concrete examples from the scientific literature to better answer these questions.
A Potpourri of Tokenizations
When I started to write this article, my original plan was to only investigate the evaluation of the recent AlexaTM from Amazon Alexa AI because it is simple and recent. However, checking the evaluation of AlexaTM led me to investigate Open AI’s GPT-3 and Google’s PaLM papers since their results are directly copied and compared in AlexaTM evaluation. I found enough material for discussion in each one of these papers. So I extracted one table from each paper that we will study to see if all comparisons and related claims are scientifically correct. Note: I didn’t contact any of the authors of these papers. Since they directly sent their papers to ArxiV (i.e., not peer-reviewed), and published related blog posts to alert the media, I assume they are sure that their evaluation and related claims are all correct, and that they accept their work to be publicly reviewed without warnings. I applied the same reasoning for my review of Meta AI’s No Language Left Behind.
Let’s do it chronologically. We begin with the GPT-3 research paper.
We are going to look at Table 3.4 (page 15 of the paper):
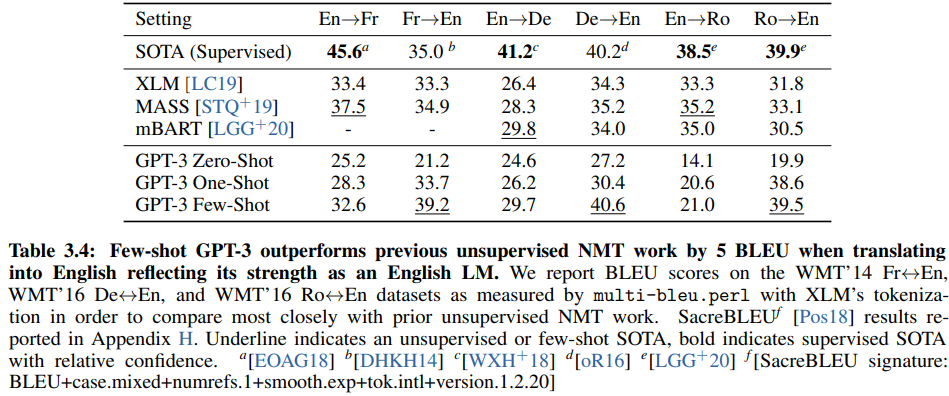
With this table, the authors of GPT-3 want to show us how GPT-3 performs in machine translation compared with previous work according to BLEU. Higher numbers mean better systems.
Are all these scores truly comparable? Presented like this in one single table, and then compared directly against each other within the text for analysis (see below), the reader is invited to assume that they are comparable and that all the numbers are computed with the same metric. Let’s check.
The first thing to check is whether the scores are copied from previous work and, if applicable, that they are correctly copied. It sounds easy, but many papers just don’t mention where do the scores come from: Whether they are copied from previous work, or recomputed by the authors. The scores from this table are correctly copied from previous work’s papers: XLM, MASS, mBART. and some of the “SOTA (Supervised).” I could not find where the score for d came from, and I had to recompute the score of b by myself for confirmation (I assume their source was the WMT Matrix which is currently offline).
Next, we have to assess how the scores are computed. This is much more challenging, but I could find the following (click on the tokenizer name to get my source): Note: To obtain this information, reading the paper is almost never enough. I had to look for the evaluation pipeline directly in the code released… It is probably correct but doesn’t give me any guarantee that the same evaluation pipeline was used to compute the numbers reported in the paper.
- SOTA a: Moses normalized+aggressive tokenization
- SOTA b: SacreBLEU 13a (for confirmation, I recomputed the score by myself on the official translation submitted by the University of Edinburgh to WMT14)
- SOTA c: SacreBLEU 13a (found in section 3.4 of the paper)
- SOTA d: ? [oR16] refers to “University of Regensburg. Fascha, 2016.” which led me nowhere. I assume it is not XLM’s tokenization which is a tokenization recipe that came after 2016.
- SOTA e: Moses tokenization + Romanian normalization for En-Ro and SacreBLEU DEFAULT (I assume they meant “13a” by “DEFAULT”) for Ro-En (found in section A of the paper)
- XLM: Moses XLM’s tokenization
- MASS: Moses XLM’s tokenization
- mBART: SacreBLEU DEFAULT (found in section A).
- GPT-3: Moses XLM’s tokenization (mentioned in the caption of the table)
That’s quite a lot of different tokenizations in one single table. This table compares tomatoes with bananas. There are at best two sets of comparable systems: {XLM, MASS, GPT-3} tokenized with XLM’s tokenization and {(b,c), mBART} tokenized with SacreBLEU 13a. Note: I’m optimistic here by assuming that they use the same version of the tokenizer (which is unlikely)…
Comparing {XLM, MASS, GPT-3} with {(b,c), mBART} is not correct and also misleading since XLM’s tokenization is likely to yield higher scores than SacreBLEU 13a, as we saw in the previous section. Let’s have look at some claims made in the GPT-3 paper given all these comparisons:
For both Fr-En and De-En, few shot GPT-3 outperforms the best supervised result
BLEU scores of b (Fr-En) and very probably d (De-En) are not computed with the same tokenization as GPT-3. They cannot be compared.
For Ro-En, few shot GPT-3 performs within 0.5 BLEU of the overall SOTA
e (Ro-En) and GPT-3 used two different tokenizations. They cannot be compared. This “0.5” BLEU difference probably doesn’t even exist.
Then:
Few-shot GPT-3 outperforms previous unsupervised NMT work by 5 BLEU when translating into English
Here, by unsupervised NMT they mean XLM. MASS, and mBART. mBART used a different tokenization. Its results cannot be compared with GPT-3 results.
At this point, I have to clarify something very important: I don’t say that GPT-3 doesn’t outperform these systems. My opinion is that GPT-3 is superior here, but this is just speculation. They don’t provide the scientific evidence to claim it. The table and claims would have been much more credible, and acceptable, if they were limited to comparisons with XLM and MASS. Adding mBART and supervised systems tokenized differently makes the evaluation incorrect.
Interestingly, the authors also provide SacreBLEU scores in the appendix of the paper. However, they chose to compute the scores with the “intl” tokenization instead of the default “13a”. I found the “intl” tokenization inflates the scores even more than XLM’s tokenization. Note: This is because “intl” tokenization adds spaces around symbols (with this line of code in SacreBLEU: regex.compile(r'(\p{S})'), r' \1 ')), hence the creation of more tokens which mechanically increases the BLEU scores.
Moving on to the next paper: Google’s PaLM. I extracted Table 13 (page 27 of the paper).

With this table, the authors of PaLM want to show us how PaLM performs in machine translation compared with previous work, mainly FLAN and GPT-3, according to BLEU.
Again, we have to check that all numbers are correctly copied from previous work. I could confirm all of them except for the 41.2 (g). I have no idea where they found it since Wang et al., (2019c) don’t evaluate their model on this task. I suspect they don’t provide the correct reference here but I may miss something since I read other papers reporting the same number with the same reference (or maybe this is just one of these numbers we forgot where they come from). I could confirm the 39.1 (h) for Ro-En but the score is not in the paper from Song et al., (2019). It is on the github webpage of the MASS project.
Then, we have to check how the scores are computed. For this paper, this is much more challenging than for GPT-3. Here, I couldn’t find any information on how PaLM’s scores are computed. There is no source code released, no citation of evaluation scripts, and not even a reference to the BLEU paper in the bibliography. This is not an easy start for our evaluation of this table…
So I have to make assumptions. I assume that they use for PaLM’s evaluation: The standard BLEU metric (Papineni et al., 2001) and the SacreBLEU intl tokenization from the T5 evaluation pipeline since this pipeline is developed by Google and also used for FLAN’s evaluation (see below) which is another Google work.
As for the tokenization of the other systems compared, here is what I have found:
- FLAN (a): SacreBLEU intl. The paper is not clear on the evaluation pipeline they used. However, the code released refers to the default BLEU implementation used in t5.evaluation.
- GPT-3 (b): Moses XLM’s tokenization (same scores as in the previous table we analyzed)
- c: Moses normalized+aggressive tokenization
- d: SacreBLEU 13a (found in section 3.4 of the paper)
- e: SacreBLEU 13a (found in section 3.2 of the paper)
- f: SacreBLEU 13a (found in section A, assuming “DEFAULT” means “13a”)
- g: ?
- h: Moses XLM’s tokenization
I assume that only FLAN and PaLM scores are comparable. Let’s have a look at the claims in the text.
First, there is this claim related to PaLM performance in machine translation against supervised baselines:
While for German-English and Romanian-English, PaLM is outperforming even the supervised baselines, we also acknowledge these baselines might be outdated as the WMT task changed its focus recently.
The problem is not that these baselines are outdated. The problem is that they are not comparable with PaLM. They use different tokenizations.
The main claim related to this table is:
PaLM outperforms all the baselines, at times very decisively with up to 13 BLEU difference.
Since GPT-3 BLEU scores are computed differently using the XLM’s tokenization, this claim is only speculation. Fortunately, this time, we can verify! As I mentioned earlier, the GPT-3 paper also provides scores computed with SacreBLEU intl tokenization that was also used by FLAN and PaLM. So we can use these scores to correct the comparisons for the “1-shot” configuration as follows:
|
Translation Direction |
GPT-3 XLM’s Tokenization (showed in PaLM) |
GPT-3 SacreBLEU intl (not showed in PaLM) |
PaLM
|
|
en-fr |
28.3 |
34.1 |
37.5 |
|
en-de |
26.2 |
27.3 |
31.8 |
|
en-ro |
20.6 |
24.9 |
28.2 |
|
fr-en |
33.7 |
35.6 |
37.4 |
|
de-en |
30.4 |
32.1 |
43.9 |
|
ro-en |
38.6 |
40.0 |
42.1 |
Using SacreBLEU intl dramatically boosts the GPT-3 scores compared to XLM’s tokenization. The gains obtained by PaLM over GPT-3 look much less impressive, some even melted by more than half. This 13 BLEU difference mentioned in the text doesn’t exist. It is possible that these gains melt even more with some undisclosed pre-processing or tokenization options used by PaLM or GPT-3.
Another thing: As prior state of the art (SOTA), PaLM’s authors curiously chose FLAN instead of GPT-3 for 0-shot and few-shot. I didn’t plan it, but let’s have a look at FLAN’s evaluation to check whether it really was the prior SOTA. The following table is extracted from the FLAN paper (Section A).
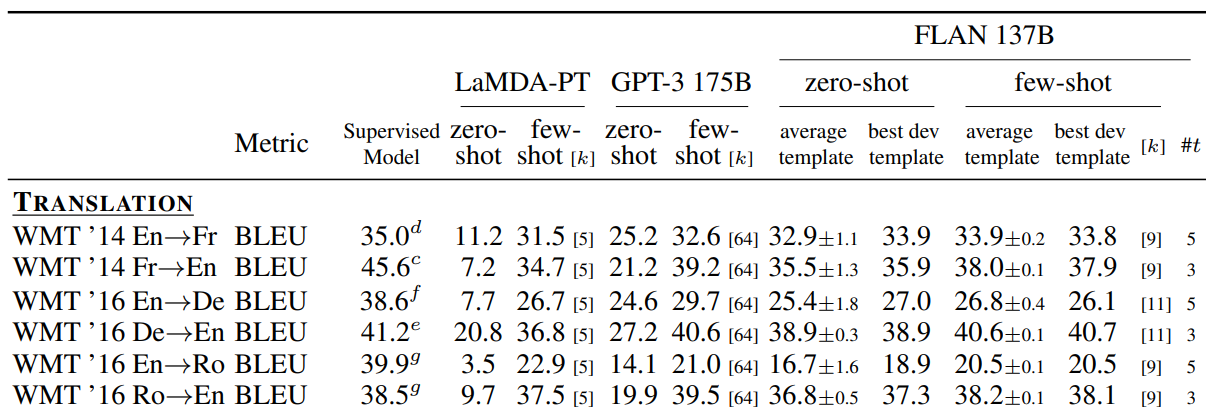
Comparisons are made with the scores computed with GPT-3 XLM’s tokenization (columns “GPT-3 175B”). Indeed, FLAN (columns “FLAN 137B”, “average template”) looks better than GPT-3 for both 0-shot… and few-shot? Not really. I’m not sure why PaLM chose FLAN for all translation directions as prior SOTA since GPT-3 has better scores than FLAN for some of them (fr-en, en-de, en-ro, and ro-en) according to this table, or am I missing something? Anyway, this kind of error is not our focus here.
Now, I change the tokenization of GPT-3 again to obtain more comparable results. We can take for instance the few-shot configuration and use the scores computed with the SacreBLEU intl provided in the GPT-3 paper.
We obtain:
|
Translation Direction |
GPT-3 XLM’s Tokenization (showed in FLAN) |
GPT-3 SacreBLEU intl (not showed in FLAN) |
FLAN |
PaLM
|
|
en-fr |
32.6 |
39.9 |
33.9 |
37.5 |
|
en-de |
29.7 |
30.9 |
26.8 |
31.8 |
|
en-ro |
21.0 |
25.8 |
20.5 |
28.2 |
|
fr-en |
39.2 |
41.4 |
38.0 |
37.4 |
|
de-en |
40.6 |
43.0 |
40.6 |
43.9 |
|
ro-en |
39.5 |
41.3 |
38.2 |
42.1 |
It appears now that GPT-3, and not FLAN, was the prior SOTA for all the translation directions. With SacreBLEU intl tokenization, GPT-3 even appears to be very competitive with PaLM, even surpassing PaLM for en-fr and fr-en. With this corrected comparison, we are now far from the claim made in the PaLM paper that “PaLM outperforms all the baselines.”
In this analysis, I assume that FLAN and PaLM don’t use the XLM’s tokenization and trust the code released for FLAN. If they used XLM’s tokenization, parts of my analysis would be wrong, and then other problematic comparisons would emerge instead of these ones.
To conclude this section, let’s have a look at the very recent work from Amazon Alexa AI: AlexaTM. This analysis will be short…
We are going to look at Table 8 of the paper.
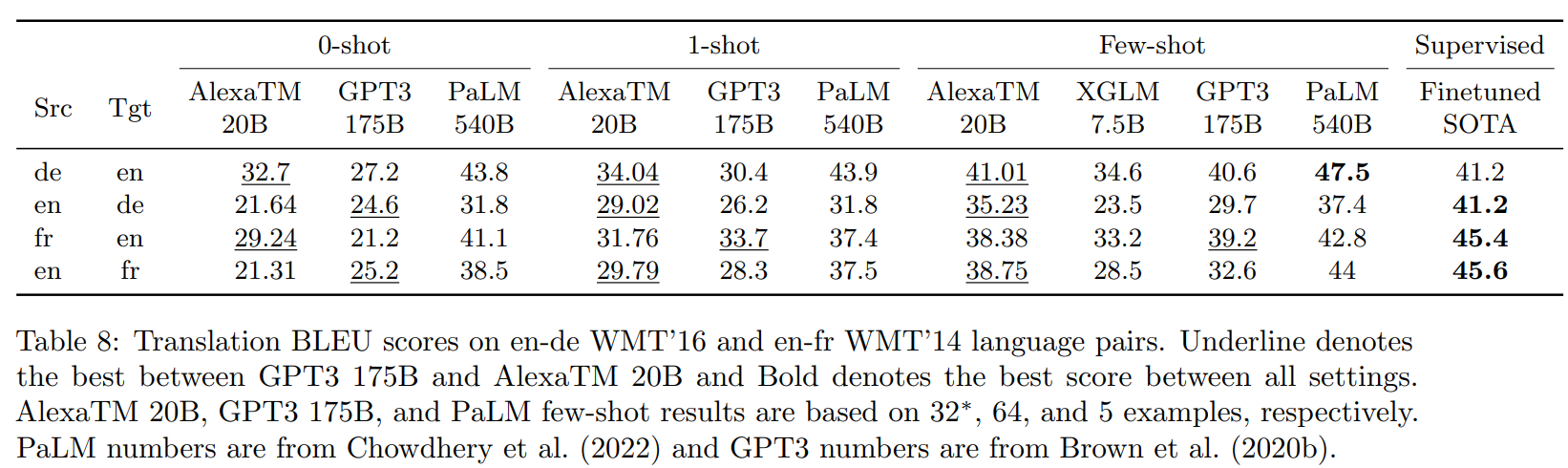
With this table, Amazon wants to show us how AlexaTM performs in machine translation compared with previous work, mainly GPT-3, PaLM, and XGLM.
I will ignore the results in the “Supervised column” since they don’t give any information about them. They are probably copied from previous papers who themselves copied the scores from somewhere else. At some point, we will forget where they really come from.
Similarly to PaLM, the authors completely forgot to mention how they computed BLEU scores. Hopefully, they will release their evaluation pipeline (the repository of the project will be updated it seems). Meanwhile, to read this table properly, we have to make some strong assumptions and speculate to a point that… I gave up and classified the whole table as meaningless. The only numbers I could confirm with certainty are the GPT-3 scores that are the same we saw in our previous examples and the XGLM scores that are computed with SacreBLEU 13a, so not even comparable with GPT-3 numbers.
A Patch for Questionable Evaluations
In machine translation research, we are lucky. There is a tool designed to guarantee the comparability between BLEU scores. This is SacreBLEU. When computing a score with SacreBLEU, a signature is generated that indicates the tokenization, the reference translation, BLEU hyper-parameters, the version, etc. The concept is simple: All scores computed by SacreBLEU are guaranteed to be comparable provided that the SacreBLEU signature is the same for all scores.
Unfortunately, SacreBLEU has never been widely adopted. I found that less than 40% of machine translation papers used SacreBLEU in 2021. Worse, as illustrated in the figure below, 20% of the papers in 2021 were still copying BLEU scores from previous work without using SacreBLEU. Note: These statistics are computed using my annotation of 913 machine translation research papers published at the ACL conferences from 2010 until 2021.
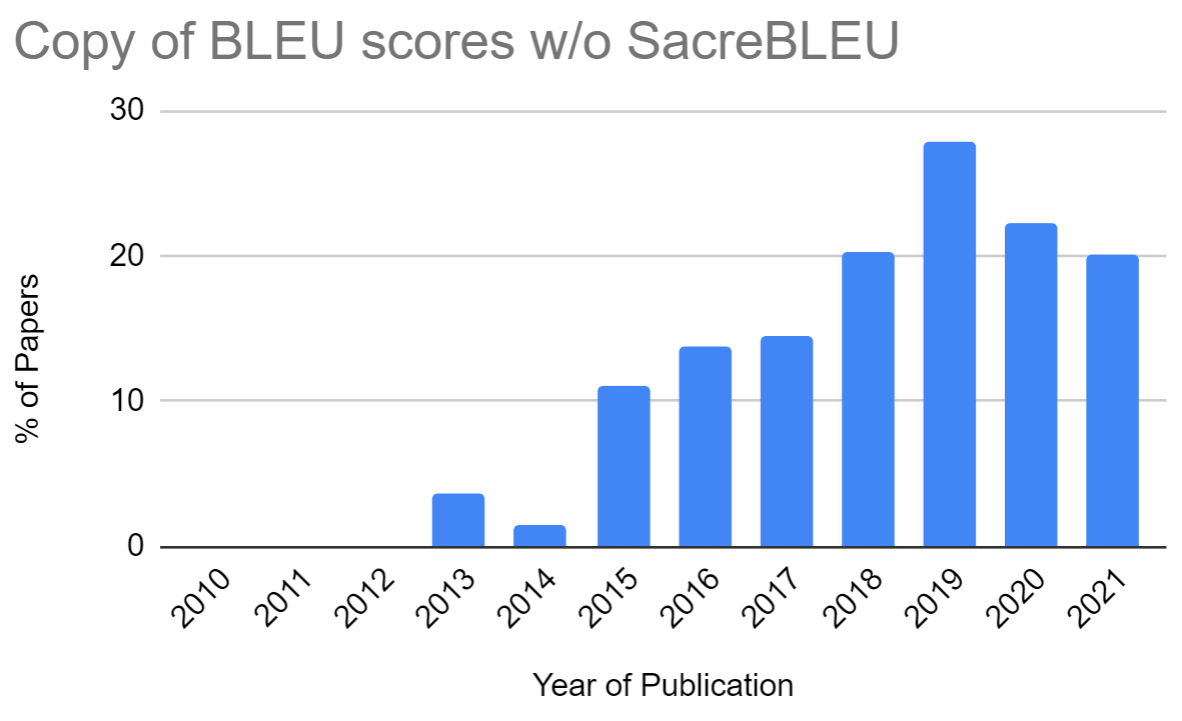
Moreover, I noticed that SacreBLEU signatures are often not provided.
SacreBLEU has been around for 4 years now. Researchers have a mature tool to compute comparable BLEU scores.
Since there is a well-known tool to guarantee comparability between copied scores, it certainly means that the machine translation research community is very well-aware of this comparability problem, so why is it not already under control?
I have really no idea why there isn’t a clear rejection of these approximate comparisons. I understand that we are not nuclear scientists and that numbers don’t mean much in machine translation, or even AI in general. Nonetheless, these numbers are used to make fantastic claims to be spread by the media and to produce scientific outcomes, such as research publications, sometimes sponsored by public fundings, that will be exploited in future work by the research community. These numbers and their comparisons should be precise and correct. This is not the case.
Copying and comparing scores to draw conclusions often costs us scientific credibility. But there are a lot of other reasons why I think we should stop comparing copied scores. Mainly:
- It prevents the adoption of better automatic evaluation metrics. For instance, COMET and BLEURT are two outstanding metrics for evaluating a machine translation system. In machine translation research. they are doomed (hopefully they have a brighter future in the industry). As long as the copy and comparisons of BLEU scores continue to be accepted, there won’t be space in scientific papers for new metrics. Showing a random 5 BLEU improvement using questionable but standard evaluation practices is much more convenient than a 0.5 COMET improvement. More than 100 metrics for machine translation evaluation have been proposed during the past 10 years, most of them have been forgotten after a few years.
- We are losing the meaning of numbers. By being copied from paper to paper, it becomes difficult to find where the numbers originally came from and how they were computed.
- Copying results is a shortcut that discourages from fulfilling some of the researcher’s scientific duties such as reproducing previous work. Even when a relevant previous work is easy to implement, or even easy to run based on a published source code, this step is skipped.
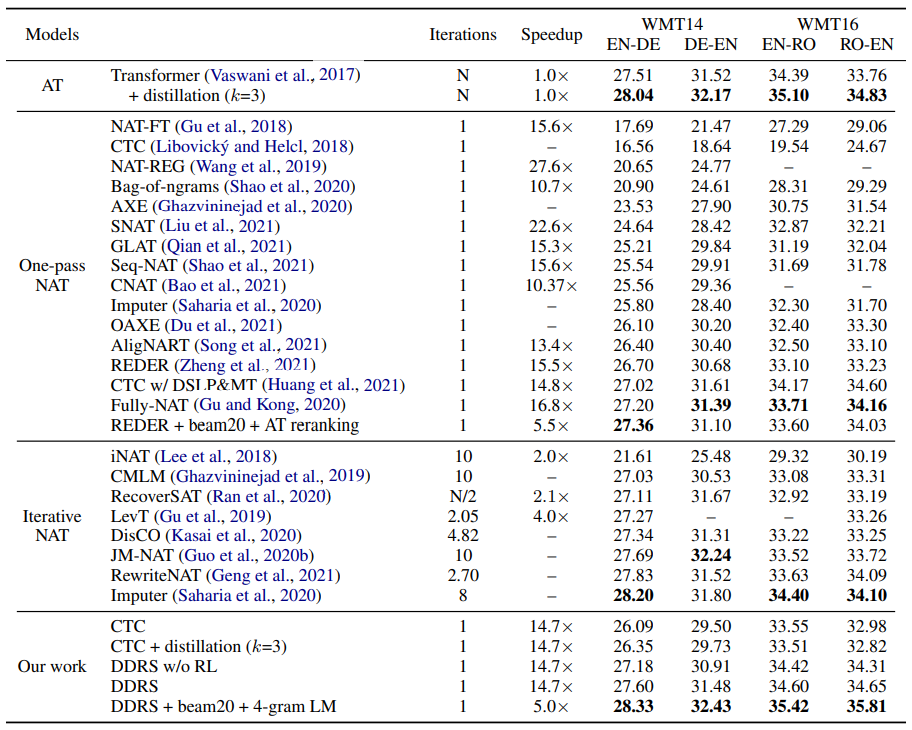
- And there is also the snowball effect. In some research areas, researchers copy entire tables from previous work and just add their own scores to the table without checking anything. Then, this growing table will be extended again by the next paper evaluating a similar approach. I’m not sure why but this is particularly well illustrated by the research on non-autoregressive machine translation where you can find tables comparing 20+ systems, such as (just an example, here I don’t blame the authors, I blame the program committee who accepted it):
Conclusion
Comparing copied results is an extremely difficult task. If Open AI, Google, Amazon Alexa AI, or even Meta AI (see my previous article) all fail to do it correctly, who can?
Checking for evaluation errors is hard, boring for most, unrewarding, and error prone. It is a tedious task that no one wants to do: not the authors, and not the reviewers.
And again, I don’t expose anything new here (except maybe the examples). The problem of comparing uncomparable scores is well-known, especially in machine translation where there were already some attempts to fight against it. I don’t expect a blog post to change anything, but I hope it will raise awareness outside of the research community.
My recommendation: Stop comparing copied scores. Comparing copied BLEU scores is not only difficult, it’s also useless. Differences between BLEU scores are often meaningless.
You may ask for examples of a correct evaluation. I can cite some recent examples of outstanding machine translation evaluations, for instance from Google, that don’t rely exclusively on BLEU or on copied scores: “High Quality Rather than High Model Probability: Minimum Bayes Risk Decoding with Neural Metrics” by Freitag et al. (2022) and “Building Machine Translation Systems for the Next Thousand Languages" by Bapna et al. (2022). Credible evaluations are possible.
Finally, if you would like to know by yourself whether an evaluation in a scientific paper is credible or not, there are numbers of indicators very easy to spot:
- The paper doesn’t mention or under-specify how its own scores are computed: no reference to the metric used, pre-processing steps and evaluation tools are undisclosed, etc.
- The paper provides and compares scores from previous work without mentioning where they come from, or how they were computed in previous work.
- The paper uses only one automatic evaluation metric and that metric is widely recognized as inaccurate.
- The paper claims a new “state of the art.”
If you want to support my work, follow me on Medium.
It is certainly possible that I made some errors in my analysis. If you think something is not correct feel free to contact me, publicly (prefered) or by DM on Twitter.