Science Left Behind
Beginning of July, Meta AI published an outstanding work: No Language Left Behind (NLLB). It presents a new translation model and datasets for 200 languages. This is a wonderful initiative that will definitely benefit many on the planet.
Update (v2): The v2 of the NLLB paper is out on ArxiV. Meta AI’s reaction to my review was very quick and cordial (despite the salt and errors in my review…). Comparisons spBLEU-BLEU and chrf-chrf++ have been replaced. Now, for most tables in the automatic evaluation section, NLLB compares its own scores with the scores copied from previous work. I believe that they did their best to make these scores as comparable as possible. They follow the machine translation evaluation standard… and thus I still strongly disagree that all these scores are comparable, but I won’t argue more about this particular paper. I will write another, more general, article on why we should stop comparing copied results. Unfortunately, I have many compelling examples from the scientific literature…
The following review has been written given the v1 of the NLLB paper. Some of my comments don’t apply anymore to the subsequent versions of the paper, but I think it is still worth reading if you are interested in better understanding, or discovering, very common pitfalls in machine translation evaluation.
It is also a scientifically dubious work. In this article, I demonstrate that many of Meta AI claims made in NLLB are: unfounded, misleading, and the result of a deeply flawed evaluation. I will also show that, following Meta AI evaluation methodology, it is very easy to obtain even higher numbers than what they have reported.
This article doesn’t target a specific audience but rather anyone who is interested to understand how researchers in AI can make exceptional claims based on truly meaningless numbers. Hopefully, this won’t be too technical. I won’t go in-depth into all the problems in Meta AI’s work to keep it short and simple.
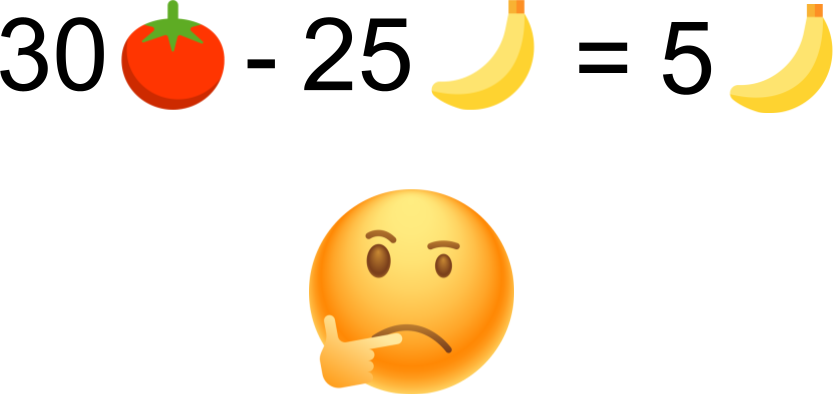
Meta AI released a scientific paper to fully explain and evaluate NLLB. In the paper’s abstract, they claim the following “Our model achieves an improvement of 44% BLEU relative to the previous state-of-the-art.” In other words, NLLB would be better than previous work. I’ll explain BLEU below, but to give you some context, a 44% BLEU improvement over the previous state of the art is something rarely seen in the machine translation research history. With this simple sentence, there is the claim of scientific progress. This claim has straightforwardly been reported by the media, often without further verifications,[1] positioning Meta AI at the top of machine translation for your language.
If you choose to publish such a big claim, you should provide very solid scientific proof with it. Otherwise you only undermine the very hard work that other research institutions have done and are doing by claiming that you did better than them without any proof.[2]
To explain how I reached my conclusion on the NLLB evaluation, I will try to demonstrate as simply as possible how Meta AI has been misled by its own resutls. I will use simple examples from NLLB and my own analogy. Then, I will show that it is actually extremely easy to beat the state of the art when using NLLB's flawed evaluation methodology. Finally, I will point out and concretely explain the main errors in their evaluation.
Shapeshifting Translations
Meta AI compared numbers from more than 20 previous studies to reach the conclusions that NLLB is significantly better than previous work. To make so many comparisons feasible, they relied on automatic evaluation metrics for machine translation evaluation: mainly BLEU and spBLEU.
Before going further, I have to explain how BLEU and spBLEU work and how different they are.
BLEU is extremely popular in machine translation research despite its well-known flaws (on which I will say nothing in this article). In brief, BLEU gives higher scores to a machine translation output that looks more similar to a given translation produced by a human, a so-called reference translation.
For instance, take the following input text,[3] in French, that we want to translate into English with Google Translate.
Input text
Cela rend les objectifs zoom peu coûteux difficiles à utiliser dans des conditions de faible luminosité sans flash.
L'un des problèmes les plus courants lors de la conversion d'un film en format DVD est le surbalayage.
La plupart des télévisions sont fabriquées de manière à plaire au grand public.
Pour cette raison, tout ce que vous visionnez sur télévision a les bords coupés en haut, en bas et sur les côtés.
Il faut donc veiller à ce que l'image couvre tout l'écran. C'est ce qu'on appelle l'overscan.
Google Translate
This makes inexpensive zoom lenses difficult to use in low light conditions without flash.
One of the most common problems when converting a movie to DVD format is overscan.
Most televisions are made in a way that appeals to the general public.
For this reason, everything you watch on television has cut edges at the top, bottom and sides.
It is therefore necessary to ensure that the image covers the entire screen. This is called overscan.
We can compare it with a reference translation by counting how many tokens in the Google translation are also in this reference. Let’s define here that a token is a sequence of characters delimited by spaces. I highlighted all the sequences of tokens from the Google translation above that appear in the reference below.
Reference translation
This makes inexpensive zoom lenses hard to use in low-light conditions without a flash.
One of the most common problems when trying to convert a movie to DVD format is the overscan.
Most televisions are made in a way to please the general public.
For that reason, everything you see on the TV had the borders cut, top, bottom and sides.
This is made to ensure that the image covers the whole screen. That is called overscan.
Given all the matched tokens, and other parameters that I won’t discuss, I can compute a BLEU score. It obtains 50.8 BLEU. This score alone means nothing. It takes meaning only when compared with another BLEU score.
The key point to understand here, and that is overlooked in most machine translation research, is that the score is computed based on the tokens. I computed the BLEU score using SacreBLEU which performs its own internal tokenization, which is basically only adding spaces before punctuation marks. This is one of the most reliable and reproducible ways to compute BLEU scores. Meta AI used spBLEU.
So what’s spBLEU? It is BLEU, but using a different tokenization. It tokenizes the Google translation and the reference translation as follows:
Google Translate
▁This ▁makes ▁in ex pensive ▁zo om ▁l enses ▁difficult ▁to ▁use ▁in ▁low ▁light ▁conditions ▁without ▁flash .
▁One ▁of ▁the ▁most ▁common ▁problems ▁when ▁conver ting ▁a ▁movie ▁to ▁DVD ▁format ▁is ▁overs can .
▁Most ▁telev isions ▁are ▁made ▁in ▁a ▁way ▁that ▁appe als ▁to ▁the ▁general ▁public .
▁For ▁this ▁reason , ▁everything ▁you ▁watch ▁on ▁television ▁has ▁cut ▁ed ges ▁at ▁the ▁top , ▁bottom ▁and ▁sides .
▁It ▁is ▁therefore ▁necessary ▁to ▁ensure ▁that ▁the ▁image ▁cov ers ▁the ▁entire ▁screen . ▁This ▁is ▁called ▁overs can .
Reference translation
▁This ▁makes ▁in ex pensive ▁zo om ▁l enses ▁hard ▁to ▁use ▁in ▁low - light ▁conditions ▁without ▁a ▁flash .
▁One ▁of ▁the ▁most ▁common ▁problems ▁when ▁trying ▁to ▁convert ▁a ▁movie ▁to ▁DVD ▁format ▁is ▁the ▁overs can .
▁Most ▁telev isions ▁are ▁made ▁in ▁a ▁way ▁to ▁please ▁the ▁general ▁public .
▁For ▁that ▁reason , ▁everything ▁you ▁see ▁on ▁the ▁TV ▁had ▁the ▁bord ers ▁cut , ▁top , ▁bottom ▁and ▁sides .
▁This ▁is ▁made ▁to ▁ensure ▁that ▁the ▁image ▁cov ers ▁the ▁whole ▁screen . ▁That ▁is ▁called ▁overs can .
The tokenization associated with spBLEU generates tokens by breaking words into smaller pieces ("▁" attached to tokens is not important here, try to ignore it). The direct consequence of using spBLEU tokenization is that we end up with a translation and a reference that both have more tokens. Mechanically, we can expect the Google translation to match more tokens from the reference since we have more tokens. The scores will go up! And indeed, the spBLEU score here is 54.8.[4]
4 points higher than the BLEU score computed above with SacreBLEU’s internal tokenization? Is the translation getting better then?
Obviously no, the translation remains the same. Comparing BLEU and spBLEU makes no sense at all. BLEU and spBLEU processed the Google translation and the reference translation differently, for evaluation purposes only. They are actually different metrics. If they were the same metrics, we wouldn't have to name them differently, right? Comparing translations using BLEU scores computed on different or even almost similar tokenizations is not almost fair, or even unfair as we often read and hear in the research community. It’s just impossible. If you want your work to be scientifically credible, you simply have to consistently compute your BLEU scores using the exact same tokenization.
Let’s take a simple analogy:
Paul has 25 bananas and Bill has 30 tomatoes.
Would you say that Bill has 5 more bananas than Paul?
Replace ‘bananas’ by BLEU and ‘tomatoes’ by spBLEU. Replace also ‘Paul’ by ‘Previous work’ and Bill by ‘NLLB’. We can now write something like:
Previous work performs at 25 BLEU and NLLB performs at 30 spBLEU.
Would you say that NLLB is 5 BLEU points better than previous work?
Meta AI did. They claimed to be significantly better than previous work because they consistently obtained better spBLEU scores than previously published BLEU scores. Actually, the contrary would have been very surprising. For a given translation, getting spBLEU scores lower than BLEU scores is an extremely difficult task (but to keep it brief I won’t do the demonstration). What’s even more beyond my understanding is that, if the goal is to get the highest scores, why don’t you optimize the tokenization so that it produces even more tokens? Why not using a chrBLEU, which could be another metric, but using characters as tokens to get as many tokens as possible, and that we would directly compare with BLEU? It’s absurde, so let’s have a look at it.
Each character becomes one token (in other words, I added spaces between characters) in the Google translation and the reference translation:
Google Translate
T h i s m a k e s i n e x p e n s i v e z o o m l e n s e s d i f f i c u l t t o u s e i n l o w l i g h t c o n d i t i o n s w i t h o u t f l a s h .
O n e o f t h e m o s t c o m m o n p r o b l e m s w h e n c o n v e r t i n g a m o v i e t o D V D f o r m a t i s o v e r s c a n .
M o s t t e l e v i s i o n s a r e m a d e i n a w a y t h a t a p p e a l s t o t h e g e n e r a l p u b l i c .
F o r t h i s r e a s o n , e v e r y t h i n g y o u w a t c h o n t e l e v i s i o n h a s c u t e d g e s a t t h e t o p , b o t t o m a n d s i d e s .
I t i s t h e r e f o r e n e c e s s a r y t o e n s u r e t h a t t h e i m a g e c o v e r s t h e e n t i r e s c r e e n . T h i s i s c a l l e d o v e r s c a n .
Reference translation
T h i s m a k e s i n e x p e n s i v e z o o m l e n s e s h a r d t o u s e i n l o w - l i g h t c o n d i t i o n s w i t h o u t a f l a s h .
O n e o f t h e m o s t c o m m o n p r o b l e m s w h e n t r y i n g t o c o n v e r t a m o v i e t o D V D f o r m a t i s t h e o v e r s c a n .
M o s t t e l e v i s i o n s a r e m a d e i n a w a y t o p l e a s e t h e g e n e r a l p u b l i c .
F o r t h a t r e a s o n , e v e r y t h i n g y o u s e e o n t h e T V h a d t h e b o r d e r s c u t , t o p , b o t t o m a n d s i d e s .
T h i s i s m a d e t o e n s u r e t h a t t h e i m a g e c o v e r s t h e w h o l e s c r e e n . T h a t i s c a l l e d o v e r s c a n .
Then we compute our chrBLEU. It yields 75.5 points, 20.7 higher than spBLEU. According to the NLLB evaluation protocol, it would be a significant improvement, and it would be the new state of the art of machine translation… while the original Google translation remained the same!
A Carnival of Numbers
Generated by https://www.craiyon.com/, prompt: “A Carnival of Numbers”
Update: all the analysis made here are made for the original NLLB paper published on ArxiV (v1). Meta AI may have forgot/overlooked to include critical information in the paper to make some claims (more) credible. They may add it later in the paper. Meta AI already informed me that corrections/clarifications are on the way. I think their reactivity is great. However, I won’t cover, or at least not in this article, all the corrections that Meta AI will make in subsequent versions to make their claims more credible. But I will update my review in case I got something wrong given the original version of the paper to acknowledge it. In case of error, for full transparency, I’ll leave and annotate the original text.
Now, let’s have a look at the NLLB evaluation for concrete examples. I will also show, but not in detail, that the problems in the evaluation are not limited to BLEU vs. spBLEU.
Meta AI claimed to outperform previous work by comparing their numbers with previously published numbers. Conclusions are drawn from Table 30, 31, 32, 35, 36, 37, and 38, that make most of the comparisons with previous work. For the sake of brevity, I will not analyze the other tables and supplementary material provided in the appendix, even though there are also similar errors in there too.
I will start with Table 32. It is one of the most illustrative examples since there are various errors of different kinds. Special thanks to my former colleague Raj Dabre for pointing out this particular table.
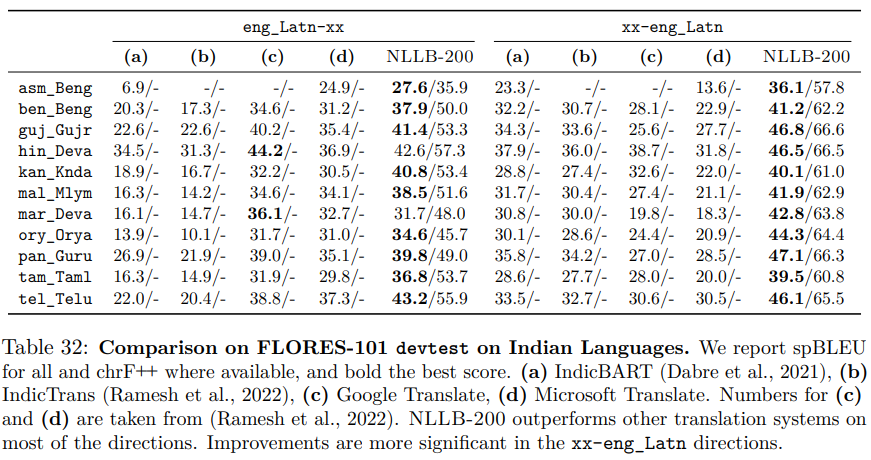
That’s a lot of numbers! All the numbers, except for the column NLLB-200, are directly copied from previously published papers: IndicBART and IndicTrans. For readability purposes, Meta AI put in bold the highest scores for each language. The column where you see bold is a statement that the corresponding system is the best. Except for two rows, all the bold numbers appear in the column NLLB-200.
In the caption of the table, we can read ‘spBLEU for all’. This is at best misleading. Actually, ‘all’ means ‘only NLLB-200’ since IndicBART and IndicTrans didn’t use spBLEU but BLEU. Yet the comparisons are made: NLLB’s spBLEU scores are higher than previous work’s BLEU scores. But does it mean that NLLB is better? Remember, are 30 tomatoes better than 25 bananas?
In the text interpreting the results we can read:

In other words, NLLB has more tomatoes than previous work has bananas. So NLLB has more bananas.
spBLEU scores are higher than BLEU scores since they are computed on smaller and different tokens. Nonetheless, is NLLB’s translation better? We simply can’t answer. And, to make things worse, IndicBART and IndicTrans are also not comparable with each other since they both also used two different tokenizations. Most of the tables listed above exhibit similar issues, but with more or less errors…
If you look at IndicBART and IndicTrans published papers to check the numbers, you will find that something else is wrong. The columns (a,b) in Table 32 are all swapped! IndicBART numbers are the numbers from IndicTrans, and vice versa.
Update: In my following analysis of Table 30, I’m totally wrong. I wrote that NLLB-200 and M2M-100 rows of Table 30 are not comparable. I didn’t read or noticed that the caption of the table mentions that the spBLEU are all using the same tokenizer FLORES-101. I double-checked and can say that the scores here are all comparable. My analysis that follows is correct but is not applicable for this table.
It gets even more questionable if you look at Table 30.
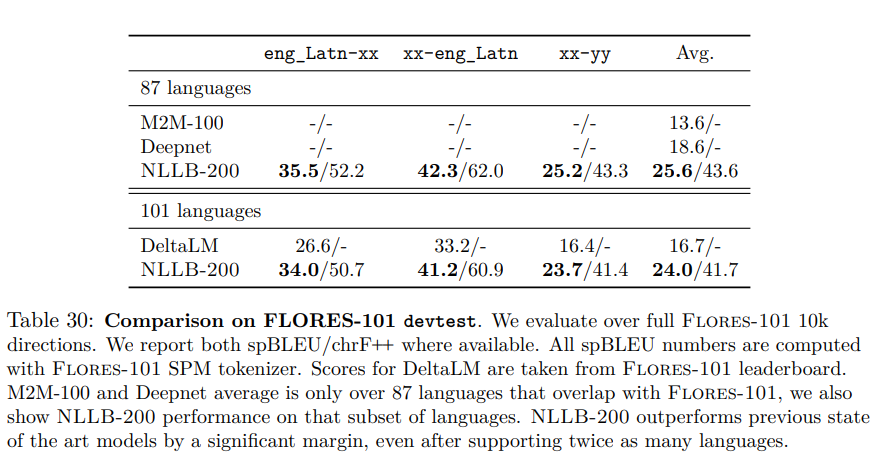
As in Table 32, Meta AI claims to be better than previous work, DeltaLM and Deepnet, while comparing BLEU scores computed differently. What is new here is that they also compared NLLB with their own previous work: M2M-100, also evaluated with spBLEU. Does this comparison make sense then? No, even if they both used spBLEU they actually used a different tokenizer which makes the comparison impossible. They make the following statement in the footnote 28:

Minor differences are differences. In this case, they matter because we are doing Science.
Compared to their work on M2M-100, one of the advances in NLLB is the addition of many more languages to the models and datasets. It includes the tokenization model. Technically, if you add more languages with different writing systems to this tokenizer, while keeping the same size for the vocabulary, you will mechanically get a vocabulary with smaller tokens. As we saw above, with smaller tokens you probably get better scores. Let’s verify!
I will take the same reference translation provided above, but this time I will tokenize it with the SPM-100 model instead of NLLB. I highlighted the new tokens in NLLB tokenization:
M2M-100 Tokenization
▁This ▁makes ▁in ex pensive ▁zo om ▁l enses ▁hard ▁to ▁use ▁in ▁low - light ▁conditions ▁without ▁a ▁flash .
▁One ▁of ▁the ▁most ▁common ▁problems ▁when ▁trying ▁to ▁convert ▁a ▁movie ▁to ▁DVD ▁format ▁is ▁the ▁overs can .
▁Most ▁telev isions ▁are ▁made ▁in ▁a ▁way ▁to ▁please ▁the ▁general ▁public .
▁For ▁that ▁reason , ▁everything ▁you ▁see ▁on ▁the ▁TV ▁had ▁the ▁bord ers ▁cut , ▁top , ▁bottom ▁and ▁sides .
▁This ▁is ▁made ▁to ▁ensure ▁that ▁the ▁image ▁cov ers ▁the ▁whole ▁screen . ▁That ▁is ▁called ▁overs can .
NLLB Tokenization
▁This ▁makes ▁in exp ensive ▁zoom ▁l enses ▁hard ▁to ▁use ▁in ▁low - light ▁conditions ▁without ▁a ▁flash .
▁One ▁of ▁the ▁most ▁common ▁problems ▁when ▁trying ▁to ▁convert ▁a ▁movie ▁to ▁DVD ▁format ▁is ▁the ▁overs can .
▁Most ▁televis ions ▁are ▁made ▁in ▁a ▁way ▁to ▁please ▁the ▁general ▁public .
▁For ▁that ▁reason , ▁everything ▁you ▁see ▁on ▁the ▁TV ▁had ▁the ▁bord ers ▁cut , ▁top , ▁bottom ▁and ▁sides .
▁This ▁is ▁made ▁to ▁ensure ▁that ▁the ▁image ▁covers ▁the ▁whole ▁screen . ▁That ▁is ▁called ▁overs can .
This tokenization generates 95 tokens against 97 for NLLB. It is only a subtle difference so we shouldn’t care that much… or should we? This is not a minor difference in my opinion. The consequence is that if you compute spBLEU with the M2M-100 tokenization, the score is 53.8 which is 1 point below NLLB tokenization. According to the machine translation research literature, 1 point is usually enough to claim that a system is significantly better. As expected, NLLB will produce higher scores than M2M-100. I will not demonstrate it, but the differences can be much larger for most languages covered by the tokenizer.
For this table, they could have easily recomputed M2M-100 spBLEU scores with the new tokenization to make the comparisons possible since they have everything at home: models and translation outputs.
Update: For the Table 31, Meta AI contacted me to mention that they are using the same tokenizer for M2M-100* and NLLB-200 systems. I could not find the information in the paper. I can acknowledge that, since the previous table’s caption mentions the tokenizer, I should have concluded that they are probably using the same tokenization here. This is a normal practice, but since I didn’t notice it in Table 30... M2M-100* and NLLB-200 are comparable. However, after a closer look to the paper and code of MMTAfrica, I could not confirm that MMTAfrica has also used the same tokenizer with the same parameters and model. They are maybe comparable, maybe not. The comparisons with chrF++ remains wrongs.
The next table is the last I will show you here: Table 31.
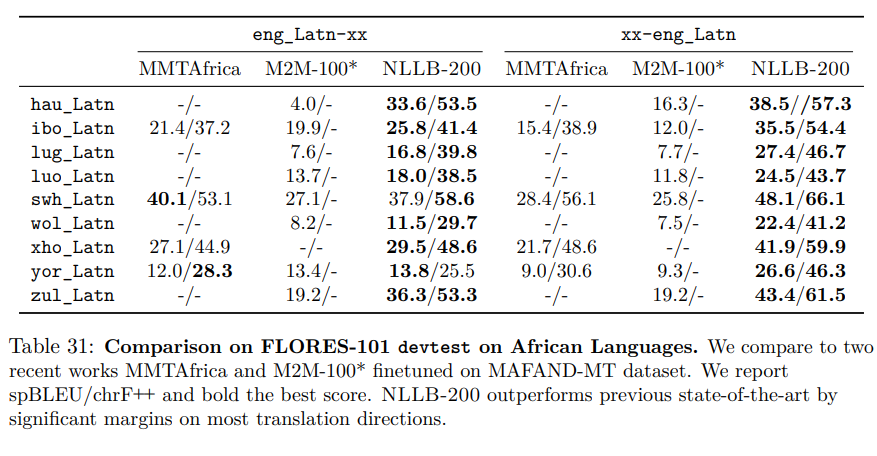
Again, we have the same problems mentioned above:
- M2M-100 and NLLB are scored using two different tokenizations, thus impossible to compare.
- MMTAfrica seems to have used M2M-100 tokenization in their paper. It can probably[5] be compared to M2M-100 but not to NLLB.
Something new: they also report on chrF++ for previous work. chrF++ is another metric which has the same purpose as BLEU. The problem here is that if you read the paper published for MMTAfrica, you will find that they didn’t use chrF++ but chrF which is yet another metric. chrF and chrF++ scores can’t be compared but are anyway compared in NLLB. It also makes the caption of Table 31 incorrect.
In Table 33, they compare NLLB against Google Translate. The scores compared are comparable. But we shouldn’t try to draw any conclusion from it… Google Translate is a black-box system, we don’t know its training data. Unless proven otherwise, we should assume, for the sake of scientific credibility, that Google has been trained on NLLB evaluating data. Since NLLB evaluating data is extracted from wikipedia, it is very likely that Google Translate saw some part of it, if not all, during its training. A problem called data leakage and that is a concern in many research domains. I refer you to a recent work from Princeton University exposing it.
In Table 35 and 36, they compared NLLB translations with the best translations submitted by participants to international machine translation competitions. Meta AI dropped their spBLEU and chose to compute BLEU scores with a recipe that “conform to the tokenization or normalization used in the current state-of-the-art” for each language. In my opinion, they are the most credible tables in this section. They probably got some comparisons that are correct. Yet, the recipe used to compute the BLEU scores may not be identical to the one used by the organizers of the competitions. They should have recomputed all BLEU scores by themselves, using the translation outputs released by the organizers for each language. This is the only way to guarantee comparability and it would have enabled the computation of other metrics, such as chrF++ that they only reported for NLLB translations.
In Table 37 and 38, they are back with the use of spBLEU, but I lost track of what they actually report. They state “We report BLEU/spBLEU/chrF++,” yet, the format of the scores reported is for instance “49.6/70.3.” I assume this is “spBLEU/chrF++,” and thus we have the comparisons between BLEU and spBLEU scores again.
Is there a simple fix?
Fortunately, yes!
Don’t make comparisons that you can’t make. This is the simple fix.
If machine translation researchers want to directly compare their work with previous work with their own metric, they have to change their evaluation practices and start releasing their translation outputs. If they release them, researchers would be able to guarantee that they compute the same metric on both their translations and previously published ones.
To the best of my knowledge, NLLB team didn’t release the translations that they have generated (but I really hope they will).
Conclusion
In NLLB, the main error made by Meta AI is a very common error in machine translation evaluation: considering that two BLEU scores are comparable even if they were computed differently.
In addition to the use of automatic metrics, Meta AI also conducted a thorough evaluation with humans to demonstrate that their translations are good. I’m not an expert in human evaluation but it looks correct to me. However, this evaluation doesn't demonstrate that NLLB generates better translations than previous work since the evaluators weren’t requested to also evaluate previous work.
What I point out in this article is obvious and very well-known by machine translation researchers (see my personal note below), including authors of NLLB with whom I discussed these pitfalls on several occasions. This kind of evaluation practices became a standard in machine translation research. If NLLB didn’t do it, many in the research community would have requested to see such comparisons with previous work, even if they are meaningless (not a problem) and misleading (a big problem). But ultimately, the choice of following these evaluation practices still belongs to the authors of the research.
Also, I should insist. Other than that, this work is truly amazing, and probably delivers higher translation quality for many languages anyway. Meta AI only follows, at the very large scale that characterizes its research, the concerning trends that we can observe in AI research.
Update (v2): Even if I strongly disagree with their performance claim compared to previous work, I do recommend having a look at what they released. Personally, I definitely recommend the use of NLLB resources for building XX-to-English translation systems, where XX is one of the languages supported by NLLB.
A more personal note
At first, when I saw Meta AI tweeting about this work, I didn’t pay much attention. I expected their claim in achieving the state of the art to be somewhat flawed as in most machine translation research papers. I could have been fine with it, but when I saw many news websites advertising NLLB, I realized that this may be a very good occasion to publicly expose once more the scientific credibility of machine translation research.
Last year, I published a meta-evaluation of hundreds of machine translation papers highlighting pitfalls and concerning trends in machine translation evaluation. All the problems I described in the NLLB evaluation are well-known and I have already exposed them, one year ago, to the research community at ACL 2021. My work was awarded by the ACL. So far, I couldn’t see any significant impact in machine translation research.
Finally, if you are doing research and you aren't sure that your evaluation is 100% correct, or at least not double-checked by external colleagues (e.g., peer-reviewed), publish your idea to protect it but don't publish your evaluation until it's correct and don't make any scientific claim until then.
I will try to write this kind of article on a regular basis to point out questionable, as well as outstanding, evaluations in AI/MT research publications. I hope it will help the research community in its mission to deliver scientifically correct conclusions.
If you want to support this work, follow me on Medium.
As usual, if you think I made an error in my analysis feel free to contact me, publicly (prefered) or by DM on Twitter.
[1] To be fair, some did fantastic work to get an external opinion on Meta AI’s claims, The Verge for instance contacted renown machine translation researchers such as Alex Fraser and Christian Federmann to get their comments on NLLB. But they contacted them only a few hours after the release of NLLB. I’m quite sure that, even with their many years of experience, they didn’t have the time to thoroughly review 100+ pages, hence their rather neutral remarks reported by The Verge.
[2] To be fully transparent, none of my previous work has been compared with NLLB, but the work of some of my former colleagues is supposedly outperformed.
[3] From the FLORES101’s dev dataset. Note that this example is already a translation from English. The French speaking reader will notice that this is a translation of a poor quality: syntax error, term inconsistency, and it doesn’t sound natural. Actually, since the dataset was created from English, Meta AI only evaluates machine translation of translations when translating into English. But this is not my point here so try to ignore it.
[4] Also computed with SacreBLEU, but with its internal tokenization deactivated.
[5] The authors didn’t provide enough details in their paper to be sure.